
Email Spam And Malware Filtering
What is E - Mail Spam?
Email spam, also known as junk email, refers to unsolicited email messages, usually sent in bulk to a large list of recipients.

Why Gmail Says emails are spam
Some common reasons for email landing in the spam folder are: Usage of spam trigger words. Promotional subject lines. Too much HTML content in the email.
In this Machine Learning Spam Filtering applications, we will develop a spam detector app using support vector machine (SVM) technique for classification and Natural Language Processing. Using tensor flow...
Support Vector Machine Introduction :
Support Vector Machine or SVM is one of the most popular Supervised Learning algorithms, which is used for Classification as well as Regression problems.
However, primarily, it is used for Classification problems in Machine Learning.
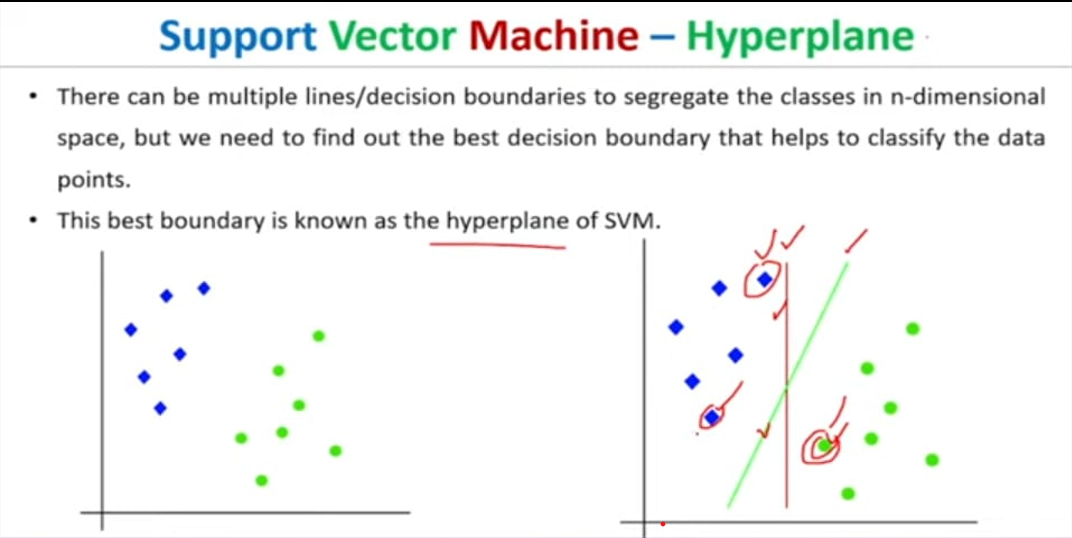
The goal of the SVM algorithm is to create the best line or decision boundary
that can segregate n-dimensional space into classes so that we can easily put
the new data point in the correct category in the future.
This best decision boundary is called a hyperplane.
Support Vector Machine Hyperplane:
The dimensions of the hyperplane depend on the features present in the dataset, which means if there are 2 features (as shown in image), then hyperplane will be a straight line.
And if there are 3 features, then hyperplane will be a 2-dimension plane.
We always create a hyperplane that has a maximum margin, which means the maximum distance between the data points.
Types Of SVM:
SVM can be of two types:
1. Linear SVM: Linear SVM is used for linearly separable data, which means if a dataset can be classified into two classes by using a single straight line, then such data is termed as linearly separable data, and classifier is used called as Linear SVM classifier.
2. Non-linear SVM: Non-Linear SVM is used for non-linearly separated data, which means if a dataset cannot be classified by using a straight line, then such data is termed as non-linear data and classifier used is called as Non-linear SVM classifier
Linear SVM

Formulas For Linear SVM:

Non-Linear SVM:

Solution Of non-linear SVM:

Code for implementing the spam mail detection system by using the support vector machine :
import pandas as pdfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.model_selection import train_test_splitfrom sklearn.svm import SVCfrom sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# Load datasetdata = pd.read_csv("spam.csv", encoding='latin-1')data = data[['v1', 'v2']] # Select relevant columnsdata.columns = ['label', 'message'] # Rename columns
# Convert labels to binary valuesdata['label'] = data['label'].map({'ham': 0, 'spam': 1})# Split the dataset into features and labelsX = data['message']y = data['label']
# Convert text data to numerical features using TF-IDFtfidf = TfidfVectorizer(stop_words='english', max_df=0.7)X_tfidf = tfidf.fit_transform(X)
# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X_tfidf, y, test_size=0.2, random_state=42)
# Train the SVM modelsvm_model = SVC(kernel='linear', C=1.0)svm_model.fit(X_train, y_train)
# Predict using the test sety_pred = svm_model.predict(X_test)
# Evaluate the modelaccuracy = accuracy_score(y_test, y_pred)print(f'Accuracy: {accuracy:.2f}')print('\nClassification Report:\n', classification_report(y_test, y_pred))print('\nConfusion Matrix:\n', confusion_matrix(y_test, y_pred))Explanation:
Dataset: The dataset used here is a CSV file named
"spam.csv"that contains labeled email messages. Make sure to have the dataset, or you can use another dataset such as UCI Spam Collection Dataset.Data Preparation:
- Columns
v1andv2are renamed tolabelandmessage. - The label is converted to binary:
hamas 0 andspamas 1.
- Columns
TF-IDF Vectorization:
- The text data is converted into numerical features using
TfidfVectorizerto represent each message as a weighted word frequency.
- The text data is converted into numerical features using
Model Training and Evaluation:
- SVM with a linear kernel is used to train the model.
- Evaluation metrics such as accuracy, classification report, and confusion matrix are used to assess the model's performance. Learn more about SVM





{kind=link}
0 Comments